随着世界模型智能体的近期成功——其拓展了基于模型的强化学习核心思想,通过学习一个可微分模型,以实现跨多样化任务的高效样本控制——主动推理(AIF)提供了一种互补的、基于神经科学的范式,可在单一由生成模型驱动的概率框架内统一感知、学习与行动。尽管前景广阔,现有实用型AIF智能体仍依赖精确的即时预测与穷举式规划;这一局限在需进行长时程(数十至数百步)规划的延迟环境中尤为突出。此外,多数现有智能体仅在机器人或视觉基准上评估,此类任务虽契合生物智能体特性,却远未达到真实工业场景的复杂程度。
针对上述局限,本文提出一种生成–策略架构,其特点包括:(i)多步隐状态转移机制,使生成模型能通过单次前瞻预测整个规划时域;(ii)集成式策略网络,既参与隐状态转移,又接收期望自由能的梯度信号;(iii)交替优化方案,利用经验回放缓冲区分别更新模型与策略;(iv)单步梯度规划机制,实现长时程规划,从而将耗时的穷举规划完全移出控制回路。
我们在一个模拟真实工业场景(含延迟与长时程特性)的环境中评估所提智能体。实证结果证实了该方法的有效性:将世界模型与AIF形式体系耦合,可构建出端到端的概率控制器,在无手工设计奖励函数、无昂贵规划开销的前提下,实现延迟、长时程环境中的高效决策。
1 引言数据驱动决策算法,尤其是强化学习(RL)领域,已取得显著进展:智能体通过与环境交互并接收反馈来学习策略(Sutton & Barto, 2018)。与此同时,深度学习为表征提取与模式识别提供了强大框架,亦支持概率建模(LeCun 等, 2015;Bishop & Bishop, 2024),推动了计算机视觉、自然语言处理、生物医学、金融及机器人等领域的进步。深度强化学习融合了上述思想——例如,在深度Q网络(DQN)中采用神经函数逼近器,即在Atari游戏中达到了人类水平性能(Mnih 等, 2015)。基于模型的强化学习(MBRL)更进一步,显式引入(学习所得或给定的)环境模型以指导学习与规划(Moerland 等, 2023)。类似地,“世界模型”(world models)概念聚焦于学习环境的生成模型,以利用其对未来结果的表征与预测能力,尤其服务于决策过程(Hafner 等, 2025);事实上,已有理论证明,通用智能体必然包含内蕴的世界模型(Richens 等, 2025)。这与认知科学中关于生物大脑的理论高度契合——后者强调内生生成模型的核心作用(Friston 等, 2021)。在更广义的理论层面,主动推理(AIF)作为神经科学新兴领域,通过内生生成模型,将感知、行动与学习统一于生物智能体之中(Friston 等, 2017;Parr 等, 2022)。
AIF植根于自由能原理(FEP),将神经推理与学习形式化为在不确定性下对“惊奇”(surprise)的最小化(Friston, 2010)。它提供了一个自洽的数学框架,通过贝叶斯推断校准概率模型,可直接从原始感官输入(即观测)中实现学习与目标导向行动(Parr 等, 2022)。该框架有望构建模型驱动、自适应的智能体——支持端到端训练,同时提供不确定性量化与一定可解释性(Taheri Yeganeh 等, 2024;Fountas 等, 2020)。与世界模型及MBRL类似,AIF亦依赖于一个环境内部模型,有助于捕获系统动力学并提升样本效率。然而,尽管AIF框架潜力巨大,其实用智能体通常仍依赖精确的即时预测与大规模规划(Fountas 等, 2020)。此类依赖会损害性能,尤其在延迟环境中——行动后果无法即时观测(RL中常表现为稀疏奖励),从而加剧了信用分配问题(Sutton & Barto, 2018)。同样,长时程任务要求在扩展时间跨度上进行高效规划,带来额外挑战。这些困难广泛存在于各类优化任务中——如制造系统(Taheri Yeganeh 等, 2024)、机器人(Hafner 等, 2020, 2025;Nguyen 等, 2024)及蛋白质设计(Angermueller 等, 2019;Wang 等, 2024)——其结果往往需历经多步操作或待全过程完成后方才显现。
本文探讨如何释放AIF框架的潜力,构建在延迟且需长时程规划的环境中依然高效的智能体。近期深度生成建模的进展(Tomczak, 2024)已在多领域实现突破——如AlphaFold达成高精度蛋白质结构预测(Abramson 等, 2024)。鉴于生成模型是AIF的核心,我们的目标是拓展其作为世界模型的能力与保真度,实现对遥远未来的预测。具体而言,我们提出一种端到端训练、符合AIF形式体系的生成–策略联合架构,其中生成模型可进行长时程推演,并在优化过程中向策略网络提供梯度信号。
本文贡献总结如下:• 提出一种符合AIF原理的生成–策略架构,支持长时程预测,并向策略提供可微分信号;• 推导出一种联合训练算法:交替更新生成模型与策略网络,并阐明如何在规划阶段通过策略梯度更新利用所学模型;• 在工业场景中实证验证该方法的有效性,凸显其对延迟与长时程任务的适用性。
本文其余部分组织如下:第2节回顾AIF形式体系与规划策略;第3节详述所提方法与智能体架构;第4节呈现实验结果;第5节总结启示并展望未来方向。
基于世界模型(world models)概念的智能体拓展了基于模型的强化学习(MBRL)的核心思想,通过学习一个可微分的预测模型,使其能在模型内部进行“想象”(imaginations),从而促进策略优化与规划(Ha & Schmidhuber, 2018;Hafner 等, 2025)。这类智能体构建能同时捕获空间与时间特性的隐变量表征,用以建模系统动力学并预测未来状态(Ha & Schmidhuber, 2018)。其中,支配该动力学的生成模型架构,及其如何被用于策略学习与规划,构成了该概念的基础。许多设计借鉴了变分自编码器(VAE)结构(Kingma & Welling, 2013),并常辅以循环状态空间模型(RSSM)以增强记忆能力、辅助信用分配(Hafner 等, 2019, 2025;Nguyen 等, 2024)。与此同时,强化学习方法(如Actor–Critic)被整合进该模型,以优化策略(Hafner 等, 2020, 2025;Nguyen 等, 2024),从而产生高度样本高效的智能体——其决策更多依赖“想象”推演,而非大量与环境交互。
主动推理(AIF)则提供了一种互补的、植根于神经科学的视角,它涵盖了预测编码理论——该理论主张:大脑在不确定性下通过最小化相对于其内生世界生成模型的预测误差来运作(Millidge 等, 2022)。AIF将大脑刻画为一个层级系统,持续执行变分贝叶斯推断以抑制预测误差(Parr 等, 2022)。其最初被提出,旨在解释生物体如何通过不断更新信念并从感官观测中推断行动,来主动控制与导航环境(Parr 等, 2022)。AIF强调观测对行动的依赖性(Millidge 等, 2022);相应地,它主张:在校准生成模型的同时,行动的选择应与偏好一致,并降低不确定性,从而统一感知、行动与学习(Millidge 等, 2022)。自由能原理(FEP)为此框架提供了数学基石(Friston 等, 2010;Millidge, 2021),且日益增多的实证研究支持其生物学合理性(Isomura 等, 2023)。基于AIF的智能体已被应用于机器人、自动驾驶与临床决策支持系统(Pezzato 等, 2023;Schneider 等, 2022;Huang 等, 2024),在不确定、动态环境中展现出稳健性能。本文采纳Fountas 等(2020)提出的AIF形式体系;该体系后续由Da Costa 等(2022)与Taheri Yeganeh 等(2024)拓展,并已被证实在不同环境(如视觉与工业任务)中均能产出高效智能体。
在主动推理(AIF)框架内,智能体采用一个集成的概率框架,该框架包含一个内部生成模型(Da Costa 等,2023),并配备推理机制,使其能够表征世界并据此行动。该框架假设为部分可观测马尔可夫决策过程(Kaelbling 等,1998;Da Costa 等,2023;Paul 等,2023),其中智能体与环境的交互被形式化为三个随机变量——观测、隐状态和动作——在时刻 t 记作 (oₜ, sₜ, aₜ)。与强化学习(RL)不同,该形式体系不依赖环境提供的显式奖励反馈;相反,智能体仅从其接收到的观测序列中进行学习。智能体的生成模型由参数 θ 参数化,定义于截止时间 t 的轨迹上,记为 Pθ(o₁:ₜ, s₁:ₜ, a₁:ₜ₋₁)。智能体的行为受“最小化惊奇”的指令驱动,该惊奇被表述为当前观测的负对数证据:−log Pθ(oₜ)(Fountas 等,2020)。当与世界交互时,智能体从以下两个角度实现这一指令(Parr 等,2022;Fountas 等,2020):
利用当前观测,智能体通过优化参数 θ 来校准其生成模型,以获得更准确的预测。数学上,该惊奇可按如下方式展开(Kingma & Welling, 2013):
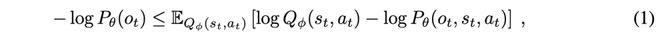
这提供了一个上界,通常被称为负证据下界(ELBO)(Blei 等,2017)。它被广泛用作训练变分自编码器的损失函数(Kingma & Welling, 2013)。在主动推理(AIF)中,它对应于变分自由能(VFE),其最小化可降低预测相对于实际观测所产生的惊奇(Fountas 等,2020;Sajid 等,2022;Paul 等,2023)。
展望未来,当智能体需要规划行动时,可获得对未来预测的惊奇估计。考虑一个动作序列——或称策略——记为 π,其中 τ ≥ t,这对应于 −log P(oₜ θ, π),该值可类比于 VFE 进行估计(Schwartenbeck 等,2019):

从概念上讲,期望自由能(EFE)中各项的贡献可解释如下(Fountas 等,2020):
(式4a)——即期望惊奇,用于度量在策略 π 下所预测结果与智能体对结果的先验偏好之间的不匹配程度。该项类比于强化学习(RL)中的奖励:它量化了预测结果与偏好结果之间的偏离程度。但与“最大化累积奖励”不同,智能体旨在最小化相对于偏好观测的惊奇。
(式4b)——即获取新观测前后,智能体对隐状态信念之间的互信息。该项激励智能体探索那些可降低其对隐状态不确定性的环境区域(Fountas 等,2020)。
(式4c)——即在给定新观测下,关于模型参数的期望信息增益。该项亦对应于主动学习或好奇心(Fountas 等,2020),反映了模型参数 θ 在生成预测中的作用。
后两项分别刻画了两种不同形式的认知不确定性(epistemic uncertainty),为智能体提供了内在驱动力,促使其主动探索并精炼其生成模型。它们在功能上类比于RL中的内在奖励,用于平衡探索–利用权衡。类似的信息探索或好奇心信号,构成了诸多成功RL算法的基础——从好奇心驱动的奖励增益(Pathak 等,2017;Burda 等,2018),到Soft Actor-Critic所优化的熵正则化目标(Haarnoja 等,2018)——并已被证实可催生高效、样本节约型的智能体。
2.2 规划策略基于模型的强化学习(MBRL)智能体通常在行动前利用其世界模型“想象”未来轨迹,以额外的计算开销换取样本效率与性能的显著提升。蒙特卡洛树搜索(MCTS)(Coulom, 2006;Silver 等, 2017)是一种典型的搜索算法,它以受限方式有选择性地探索有前景的轨迹。其有效性在AlphaGo Zero(Silver 等, 2017)中得到突出体现,后续MuZero进一步将学习所得的隐状态动力学模型直接嵌入搜索循环中(Schrittwieser 等, 2020)。在主动推理(AIF)框架中,智能体在执行动作前的规划目标即为最小化期望自由能(EFE);数学上,该目标对应于负的累积EFE,即 G,定义如下:
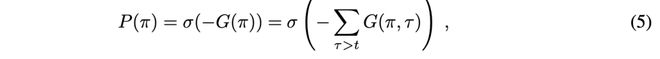
其中 σ(·) 表示 Softmax 函数。智能体在策略 π 下,通过其生成模型进行轨迹推演(roll-outs),以评估期望自由能(EFE)。然而,对所有可能的 π 计算此值是不可行的,因为策略空间会随规划深度呈指数增长。Fountas 等(2020)引入了一个辅助模块,并结合 MCTS 以缓解这一障碍。他们提出一个识别模块(Piché 等, 2018;Marino 等, 2018;Tschantz 等, 2020),参数化为 φₐ,形式如下:Habit, Qφₐ(aₜ),该模块利用从 MCTS 返回的先验分布 P(aₜ) 来近似动作的后验分布(Fountas 等, 2020)。这类似于生物智能体中快速且习惯性的决策机制(Van Der Meer 等, 2012)。他们使用该模块在规划过程中快速扩展搜索树,随后计算叶节点的 EFE 并沿轨迹反向传播。迭代地,最终形成一棵加权树,并对访问过的节点进行记忆更新。他们还利用规划器策略与“习惯”之间的 Kullback–Leibler 散度作为精度,调节隐状态(Fountas 等, 2020)。
另一种增强规划的方法是采用混合时域(hybrid horizon)(Taheri Yeganeh 等, 2024),即在规划过程中,将基于即时下一步预测的短视 EFE 项,与一个额外项结合,以兼顾更长时域。Taheri Yeganeh 等(2024)采用了一个 Q 值网络 Qφₐ(aₜ),用于表征动作的摊销推理(amortized inference),该网络以无模型方式、仅依赖外在价值进行训练。这些项随后在规划器中组合如下:
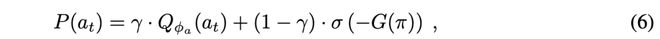
现代世界模型智能体越来越多地将前瞻转移到潜在空间;PlaNet(Hafner 等人, 2019)在使用潜在超调训练的 RSSM 内部使用交叉熵方法 rollout,而 Dreamer 家族(Hafner 等人, 2020; 2025)通过数百条想象轨迹传播解析价值梯度,无需树搜索。EfficientZero(Ye 等人, 2021)将 AlphaZero 风格的 MCTS 与潜在空间想象相结合,仅用 100k 帧就超越了人类 Atari 表现。这些方法通常将多步模型 rollout 与一个演员(策略)耦合,并且经常与一个在想象过程中查询的评论家(价值)网络结合。在每个模拟步骤中,
策略提出下一个动作,而评论家提供一个引导值,从而实现高效的多步前瞻,而无需枚举完整的动作树。Taheri Yeganeh 等人 (2024) 没有顺序采样动作和状态,而是训练了多步潜在转换,条件为重复动作;在规划期间,单个转换预测结果,同时保持一个动作固定若干时间步。这样,通过重复动作模拟捕捉了动作在长时间范围内的影响。虽然它可以与 MCTS 结合,但这种近似有助于在高度随机控制任务中,基于单一前瞻的 EFE 区分不同动作(Taheri Yeganeh 等人, 2024)。它仅限于离散动作,无法超越重复动作,并且仍需要在每次动作前通过 EFE 计算进行规划。
3 深度主动推理智能体从整合习惯的 MCTS 到混合视野与基于梯度的潜在想象,当前最先进的智能体日益将策略学习与规划相结合,以捕捉对可扩展性与样本高效控制至关重要的长期效应。其中,一种突出的方法是潜在想象(latent imagination),尤以 Dreamer 系列智能体(Hafner 等,2025;2019;2020)为代表——它们利用递归状态空间模型(RSSM)在潜在空间中执行序列 rollout。然而,除其计算成本较高外,该方法还面临误差随网络反复推断与采样而累积的风险。这些模型通过在每条潜在状态轨迹上采样动作,将策略网络嵌入潜在空间,因而策略优化依赖于模型想象中大量采样步骤。
一种更简洁的策略是:假定生成模型已知策略函数的确切形式——换言之,即模型拥有策略网络本身的参数。我们可训练此类模型:一旦给定用于在该视野内与环境交互的策略参数,便可通过单步前瞻(single look-ahead)直接生成对远期未来的预测。由此,期望自由能(EFE)可直接在整个视野上计算,并可通过反向传播梯度以最小化 EFE,从而引导智能体朝向其内在与外在目标。鉴于策略通过 EFE 的梯度下降进行优化,该方法可自然扩展至离散与连续动作空间,而不再局限于早期主动推理(AIF)智能体实现中所采用的离散动作选择(如 Fountas 等,2020)。本文采用这种与主动推理一致的生成式策略建模(generative-policy modeling)方案,未引入通常用于进一步增强世界模型或 AIF 智能体的额外机制。
该智能体至少包含一个直接与环境交互的策略网络,以及一个用于优化该策略的生成模型。在策略条件下,生成模型构成了主动推理(AIF)的核心,并可通过多种架构实例化。在本工作中,我们采用一种通用但常用的自编码器组合结构(Fountas 等人, 2020),以实例化第 2.1 节中的形式化体系,该体系要求如图 1 所示的紧密耦合模块。通过利用摊销推断(Kingma & Welling, 2013; Marino 等人, 2018; Gershman & Goodman, 2014)来扩展推断能力(Fountas 等人, 2020),生成模型由两组参数化:θ = {θs, θo} 用于先验生成,φ = {φs} 用于识别。相应地,编码器Qφs(st) 通过将当前采样的观测值 õt 映射到潜在状态 st 的后验分布,执行摊销推断(Margossian & Blei, 2023)。此处的关键区别在于,我们不再在潜在动力学内部采样动作,而是引入了一个策略函数——或称演员(Actor)——Qφa(at õt),该函数自身以参数 φa 推断出动作的分布。因此,我们为该函数本身引入了一个显式表示,映射关系为 Π: Qφa → π̂,从而得到 π̂(φa)。这种方法在神经隐式表示中很常见(Dupont 等人, 2022);最近的研究还表明,具有多样化计算图的神经函数可以被高效嵌入(Kofinas 等人, 2024)。在演员条件下,转移模块Pθs(st+1 s̃t, π̂) 将潜在动力学外推至规划视野 H,根据时间 t 采样的潜在状态,生成 st+H 的分布,而演员——以 φa 表示——在整个视野内被假定为固定不变。最后,解码器Pθo(ot+H s̃t+H) 将预测的潜在状态转换回未来观测值的分布。生成模型中的这三个模块均由一个神经网络实现,该网络输出对角多元高斯分布的参数,从而近似一个预选的似然族。它们可以通过最小化 VFE(公式 1)进行端到端训练,而演员则通过最小化 EFE(公式 4)进行优化——使用来自已校准模型的预测。通过这种方式,智能体统一了形式化体系中推导出的两种自由能范式。
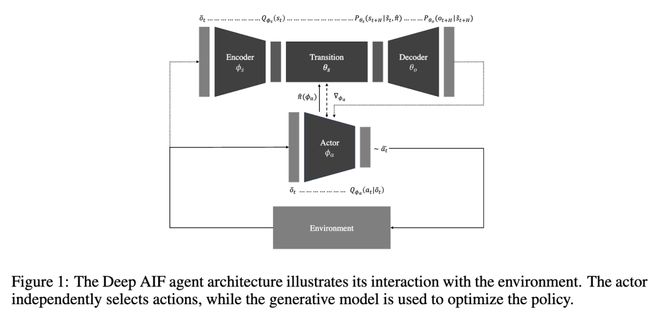
除了演员(Actor)和转移模块(Transition)——它们通过单步前瞻处理潜在动力学——之外,该架构类似于变分自编码器(VAE)(Kingma & Welling, 2013);然而,其他生成机制,例如扩散模型或基于记忆的 RSSM 模型,也可扩展以支持相同的目标。
我们提出了一种简洁而有效的公式化方法,将演员嵌入生成模型中,使其作为规划器通过梯度下降最小化期望自由能(EFE)。在固定策略 π̂(φₐ) 的条件下,模型生成预测分布 Pθ(oₜ₊ₕ φₐ),并由此计算 EFE,记作函数 Gθ(õ, φₐ)。策略优化随后根据梯度 ∇φₐ Gθ(õ, φₐ) 更新演员参数。大多数世界模型智能体通过在想象过程中采样动作引入随机性,从而促进探索——通常辅以策略梯度中的辅助项。这导致了对想象轨迹上策略的蒙特卡洛估计,然后基于回报对其进行微分(Hafner 等人, 2020)。相比之下,我们的方法假设策略的确切形式已整合进动力学中,而探索则由基于生成模型的主动推理(AIF)形式化框架驱动。
为了有效估计公式 4 中 EFE 的不同组成部分,Fountas 等人 (2020) 采用了多层次的蒙特卡洛采样。虽然他们的原始公式包含了在多步视野上的采样动作,但在使用具有深度时间超调的集成式演员时,相同的结构和采样方案仍具优势。类似地,我们采用祖先采样来生成预测 Pθ(oₜ₊ₕ φₐ),并在网络中利用 dropout(Gal & Ghahramani, 2016)。它与从潜在分布中进一步采样相结合,以计算计算 EFE 项所需的熵。关键的是,在 AIF 框架下,智能体需要一种对预测的先验偏好来引导行为——这通过外在价值(即公式 4a)进行形式化表达。因此,我们定义了一个解析映射 :Pθ(oτ) → [0,1],将预测分布转换为连续的偏好谱。
不同于依赖累积奖励回报的强化学习(RL),这种公式化允许智能体表达更通用、更细致的偏好形式。在实践中,为 RL 智能体设计合适的奖励函数仍是一项困难的任务,往往导致稀疏或手工设计的信号,其设计和计算成本高昂。然而,偏好的灵活性也带来了挑战——尤其当智能体拥有复杂的偏好空间,并且必须依赖短视的 EFE 近似时。我们的方法通过优化深度时间预测下的规划,缓解了这一问题,并支持对外在价值进行更长期的评估。
在训练过程中,生成模型逐步学习不同的演员参数 φₐ 如何影响动态演化;而在策略优化阶段,该已习得的动态模型则被用于对演员进行微分,以降低其 EFE(期望自由能)或“意外”(surprise)。有效策略学习的关键在于世界模型的准确性——这是主动推理(AIF)框架(Friston 等,2010;Parr 等,2022;Fountas 等,2020)及预测编码(Millidge 等,2022)的理论基础。
为改进模型训练,我们引入了经验回放机制(experience replay)(Mnih 等,2015),使用经验记忆/缓冲区 M,从中采样经验批次进行训练,同时确保每个批次均包含最近一次的经验。我们针对这些经验计算公式 1 中的 VFE(变分自由能),并采用 β-正则化对模型进行训练。
在模型更新后,我们在长度为 H 的想象轨迹中,对一批观测值(包括先前与当前观测)计算 EFE 并对其进行微分,从而以类似于世界模型方法的方式(Hafner 等,2020;2025;Ha & Schmidhuber,2018)训练演员。由此形成一个联合训练算法九游智能体育科技(算法 1),交替更新生成模型与策略,并借助该模型通过策略梯度引导规划。
这种方法——即策略学习(policy learning),而非显式的动作规划——缓解了 EFE 的“有限视野”(bounded-sight)限制:由于策略在规划视野内多样化的场景中被迭代训练,其有效视野可延伸至名义视野 H 之外。近期基于 AIF 的智能体研究也强调了将策略网络与 EFE 目标相结合的优势(Nguyen 等,2024)。
训练完成后,当智能体模型被固定,仍可利用该模型进行规划。具体而言,可每隔 H 步在观测层面上施加一次基于 EFE 的梯度更新,从而对策略进行即时微调,以适配当前短期视野。
大多数现有的主动推理(AIF)智能体已在一系列通常由生物体(如人类和动物)执行的任务中展现出有效性。这些任务往往涉及基于图像的观测(Nguyen 等,2024)。例如,Fountas 等人(2020)在 Dynamic dSprites(Higgins 等,2016)和 Animal-AI(Crosby 等,2019)上评估了其智能体——这些任务生物体通常可较轻松完成。AIF 还已成功应用于机器人领域(Lanillos 等,2021;Da Costa 等,2022),包括物体操作(Nguyen 等,2024;Schneider 等,2022),与人类自然行为高度一致。这种有效性主要归因于 AIF 深植于对生物大脑中决策机制的理论建模(Parr 等,2022)。
然而,将 AIF 应用于更复杂的领域——例如工业系统控制——则面临显著挑战。即便人类在这些场景中也可能难以设计出高效策略。此类环境通常具有高度随机性,短期观测轨迹易被噪声主导,从而使得以自由能优化为目标的学习与动作选择变得困难。相比之下,世界模型智能体通常采用基于记忆(例如循环)架构(Hafner 等,2020;2025),因此该问题对其影响较小。此外,现实环境常混合离散与连续观测模态,加剧了生成与采样预测的复杂性。延迟反馈与长视野需求进一步挑战了 AIF 框架下的规划能力。另外,诸多现实任务需高频、快速决策,并在非回合制且高度随机的环境中维持长期稳定表现。
我们在一个经过验证的、高保真的工厂级工业仿真器中(Loffredo 等,2023b)评估了本方法,并在(Taheri Yeganeh 等,2024)提出的可证明存在延迟、长视野设定下进行测试。该源于真实世界的测试平台为验证本概念提供了具挑战性且具代表性的基准:它要求智能体进行长视野规划,以引导一类高度随机问题走向期望性能目标(详见附录 B)。
为验证本智能体在上述环境中的性能,我们采用了严格的评估方案(详见附录 D),其核心基于算法 1。不同于以往借助与多个环境实例并行交互以提升训练效率的工作(Fountas 等,2020),我们的智能体在每个训练轮次(epoch)中仅与单一环境实例交互,反映了更具挑战性的设定。随后,我们在若干随机初始化的环境中评估训练所得智能体性能,并选取表现最佳的实例进行为期一个月的仿真运行,以评估其能效与产量损失,并与基线场景(即无任何控制、设备持续运行)进行对比。
我们还构建了一个组合式偏好得分(compositional preference score)——类比于强化学习中的奖励函数——基于时间窗口内的关键绩效指标(KPI),涵盖能耗与产量,作为智能体整体性能的综合指标;该得分本身亦构成智能体观测的一部分。为在潜在空间中进一步施加正则化、使其逼近标准正态分布,我们在 Sigmoid 函数的非饱和区间内使用该函数。由于我们需编码演员函数(actor function)——其本质是一个计算图(Kofinas 等,2024)——我们采用了一个简洁的、非参数化的映射 Π:将输入与第一隐层及输出层的值进行拼接。鉴于其输入–输出结构及模型对该映射的持续训练,该映射可有效近似演员的神经函数(详见附录 C)。
我们严格依据上述方案,在完全复现真实生产系统的环境中实现了本智能体(参数经验证符合实际工况)。图 2 展示了在超前视野 H = 300 条件下的智能体性能:在每轮训练(100 次迭代)后的评估中,智能体所生成观测的偏好得分持续提升(图 2a),且该提升与能效增长正相关(图 2b)。值得注意的是,用于策略更新的想象轨迹的 EFE(图 2c)随智能体对系统控制能力的增强而下降;这一趋势同时体现在 EFE 的外在价值项与不确定性项中。
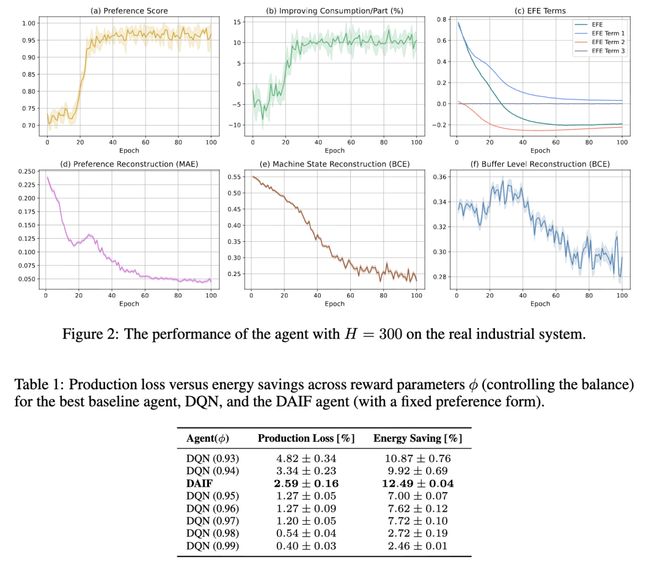
由于策略优化高度依赖于一个鲁棒生成模型的学习——且演员被显式整合于其中——智能体逐步提升了其预测能力,并在观测空间的连续部分(图 2d,偏好得分)与离散部分(图 2e,f,机器与缓冲状态)均降低了重建误差。尽管 EFE 与整体性能最终趋于稳定,生成模型仍持续改进,表明对未来观测的完全重建并非实现有效控制的必要条件。
最后,我们在十次重复的、为期一个月的仿真交互中评估了训练完成的智能体,并在规划过程中每 H 步施加一次梯度更新。Loffredo 等人(2023a)在同一环境中测试了多种无模型强化学习智能体(包括 DQN、PPO 与 TRPO),在不同奖励参数 φ 下,DQN 表现最优且接近理论最优解。如表 1 所示,深度主动推理(DAIF)智能体超越了最佳基线:在保持产量损失可忽略的前提下,单位产量的能源效率提升了10.21% ± 0.14%。
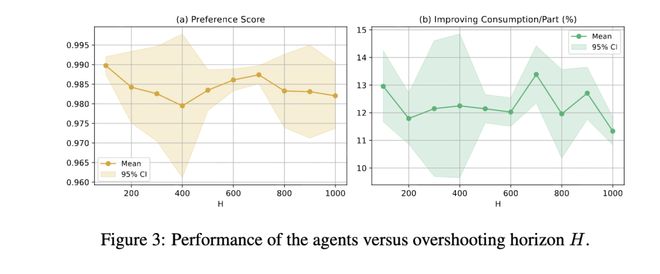
深度的影响:即使超前视野更长(例如 H = 1000 步),智能体仍能提升性能。我们进行了不同超前视野 H 的实验,以评估智能体的性能。如图 3 所示,我们报告了验证阶段最佳轮次所对应的偏好得分,并提取了能耗效率提升的百分比。结果表明,即使在更长的超前视野下,智能体仍能学习到鲁棒的策略。
我们提出了深度主动推理(Deep Active Inference, DAIF)智能体,其将多步潜在转移与一个显式、可微分的策略整合于单一生成模型内部。通过将动态模型超前预测至长视野,并将期望自由能(EFE)梯度反向传播至策略中,该智能体无需进行穷举式的树搜索即可完成规划;它可自然扩展至连续动作空间,并保持主动推理中驱动行为的认知性探索–利用平衡(epistemic–exploration balance)。我们在一个高保真工业控制问题上对 DAIF 进行了评估,其特征复杂性在以往基于主动推理的研究中鲜有触及。实证表明,DAIF 在高度随机、反馈延迟且需长视野规划的环境中,成功实现了模型学习与控制之间的闭环协同:仅需每 H 步施加一次梯度更新,训练完成的智能体即可有效规划并取得优异性能——超越无模型强化学习基线;与此同时,其世界模型即便在策略趋于稳定后,仍持续提升预测精度。
局限性与未来工作:尽管预测 H 步转移避免了昂贵的逐步规划循环,智能体仍需在每 H 次交互后收集经验并存入回放缓冲区以供训练,因此其样本效率仍有提升空间。为在每次新环境交互后更新世界模型——从而反映视野内不断演化的演员参数——我们需要一个算子来聚合该序列的演员表征。循环模型(recurrent models)是自然的选择,但其序列展开会引入延迟,并可能阻碍梯度流动。一种更轻量的替代方案是将 H 个嵌入视为(近似)无序集合,并采用集合函数(set function)进行聚合(Zaheer 等,2017);在集合池化之前,可将简单的位置嵌入(如正弦位置编码,Vaswani 等,2017)与嵌入拼接,以保留时序结构。该方法允许我们将视野分段处理——甚至细化至单步粒度——同时仍可通过聚合当前策略表征支持 EFE 梯度的反向传播。
此外,(神经)算子学习(operator-learning)技术有望实现函数空间中分辨率不变的聚合(Li 等,2020;Lu 等,2021)。其他可能的拓展方向包括:
在非平稳环境中快速适应——这正是无模型智能体常面临困难之处——仍是一个极具前景的研究方向。
总体而言,本工作架起了神经科学启发的主动推理与当代世界模型强化学习之间的桥梁,证明了一个紧凑、端到端的概率性智能体,可在那些人工设计奖励函数与逐步规划均不切实际的领域中实现高效控制。

















