在物理测量中,从实验数据中估计连续参数的精度受限于系统所携带的费舍信息(FI)——它刻画了未知参数在观测数据中的可辨识度。随着人工神经网络被广泛引入实验测量与反演分析,理解它们在内部如何处理、传递并保留这些与参数相关的信息,成为一个关键问题。本文提出了一种方法,用于监测费舍信息在神经网络中的流动过程,从输入层到输出层进行追踪。研究表明,当网络达到最优估计性能时,FI传输达到最大;若继续训练,信息反而开始损失,对应过拟合的出现。该工作不仅揭示了神经网络学习的物理机制,还提出了一种基于FI的“无模型早停”准则,为深度学习的高效与可解释训练提供了新思路。

在现代科学研究中,人工神经网络( ANNs)已成为从实验数据中提取规律、估计参数的重要工具。无论是在光学成像、量子测量,还是复杂材料建模中,神经网络都展现出超越传统算法的强大表现。然而,研究者们提出了一个极具洞察力的问题:
当神经网络学习估计一个物理参数时,信息是如何在层与层之间流动、损失或被压缩的?
近期,来自维也纳工业大学、格拉斯哥大学、鲁尔大学波鸿和法国格勒诺布尔大学的研究团队提出了一种全新的分析框架,利用费舍信息(FI)来定量追踪神经网络中与待估参数相关的信息流动。他们发现,网络的学习过程可被视为费舍信息逐步守恒的演化过程;当信息传输达到最大化时,网络也恰好实现最优的估计性能。相关成果为深度学习提供了一个具有物理意义的解释路径,并提出了无需验证集的“信息早停”准则。
传统的信息论研究通常依赖互信息(Mutual Information, MI)衡量输入与输出之间共享的信息量,但在高维连续空间中,互信息的计算往往极其困难,并可能在确定性映射中出现发散。相比之下,FI关注的是系统对未知连续参数的响应灵敏度,直接与参数估计的精度极限——克拉美–罗下界(Cramér–Rao Lower Bound, CRLB)相关。
本研究的出发点在于:不仅仅考察网络参数的不确定性,而是追踪输入数据中关于物理参数的信息在网络内部的传输过程。为此,研究团队提出九游体育科技了一个可计算的近似指标——线性费舍信息(Linear Fisher Information, LFI)。LFI只依赖样本的均值与协方差即可估计信息量,无需显式知道数据的概率分布,从而能够在复杂的深度网络中高效计算并逐层追踪信息变化。
为验证理论框架,研究团队设计了一个具有代表性的物理实验:在光学显微镜下,对一个印有“Space Invader”图案的微小物体进行水平位移测量(如图1)。实验条件被刻意设置为极低信噪比(约 13%),以模拟在噪声主导环境下的极限参数估计问题。
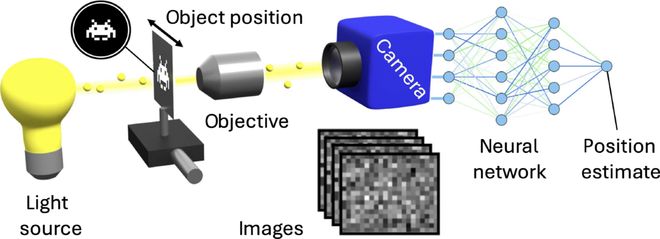
图1:左侧光源发出的光束照射在刻有“space invader”图案的玻璃载片上。透过物镜到达相机的光场强度包含关于目标水平位置 θ 的FI。实验所得图像被输入ANN进行训练,用于预测参数。神经网络需尽可能保留FI,才能实现对 θ 的高精度估计。
在这一任务中,神经网络被训练来预测物体的水平位置参数 θ。研究者在训练过程中实时计算各层的LFI,以监测信息在网络中的传播规律。结果表明:
当模型性能达到最优时,输出层的FI接近输入层,表明网络几乎保留了输入数据中关于参数的全部有效信息。
在模拟数据中,这种“信息守恒”关系几乎完美成立;而在线%的信息得以保留,主要受限于实验噪声和参数取值范围(如图2)。
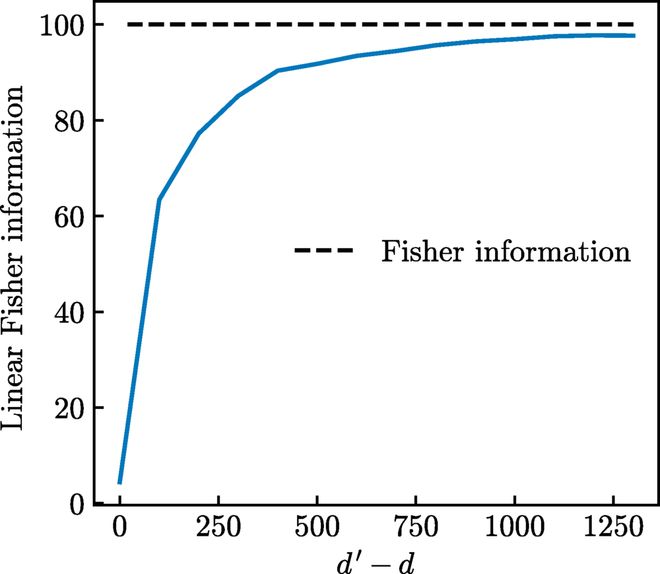
图2:数值模拟数据的LFI最大化过程。曲线显示LFI在连续高维嵌入下的变化趋势。虚线为理论计算的真实FI,用于验证算法收敛性。
深度学习中,判断训练何时结束是一项长期存在的挑战。通常做法依赖验证集监控误差变化,但这一经验性方法缺乏理论依据。本文基于FI框架提出了一个物理意义明确的早停判据:当模型的均方误差(MSE)达到由FI决定的克拉美–罗下限CRLB时,网络已提取完全部可用信息。此时若继续训练,网络将开始拟合噪声,导致过拟合现象。
这一条件可通过简单的乘积形式:MSE × I ≈ 1来检验。实验表明,该准则预测的最佳停止时刻与验证集误差最小点高度一致,但无需额外数据集即可实现训练控制,为信息驱动的模型优化提供了实用工具(如图3)。

图3:归一化均方误差(MSE)随训练历元的变化。 (a) 为带高斯噪声的模拟数据,(b) 为实验数据。深色曲线为验证损失,浅色曲线为训练损失。虚线的位置,对应训练的最佳停止点。
这项研究为理解深度学习的内部机制提供了新的定量化视角。通过追踪费舍信息在神经网络中的传播路径,研究者揭示了一个可能的普遍规律:神经网络的学习过程可被理解为费舍信息逐步趋于守恒的过程。
这一观点不仅有助于解释网络在不同训练阶段的表现差异,也为模型结构设计提供了新的启发。未来,研究者计划将这一框架扩展至带有残差连接的ResNet结构、物理神经网络(Physical Neural Networks)及更广泛的实验数据分析任务中。
在更宏观的意义上,这项工作展示了信息论与深度学习、实验物理的融合潜力。当信息流动被视为科学系统的共同约束原则,我们或许能够在人工智能与自然智能之间,找到一种更深层次的对应关系。
集智俱乐部联合上海交通大学副教授张拳石、阿里云大模型可解释性团队负责人沈旭、彩云科技首席科学家肖达、北京师范大学硕士生杨明哲和浙江大学博士生姚云志共同发起。本读书会旨在突破大模型“黑箱”困境,尝试从以下四个视角梳理大语言模型可解释性的科学方法论:
自上而下:神经网络的精细决策逻辑和性能根因是否可以被严谨、清晰地解释清楚?
复杂科学:渗流相变、涌现、自组织等复杂科学理论如何理解大模型的推理与学习能力?
五位发起人老师会带领大家研读领域前沿论文,现诚邀对此话题感兴趣的朋友,一起共创、共建、共享「大模型可解释性」主题社区,通过互相的交流与碰撞,促进我们更深入的理解以上问题。无论您是致力于突破AI可解释性理论瓶颈的研究者,探索复杂系统与智能本质的交叉学科探索者,还是追求模型安全可信的工程实践者,诚邀您共同参与这场揭开大模型“黑箱”的思想盛宴。
读书会已于2025年6月19日启动,每周四晚19:30-21:30,预计持续分享8-10周左右。

特别声明:以上内容(如有图片或视频亦包括在内)为自媒体平台“网易号”用户上传并发布,本平台仅提供信息存储服务。
泽连斯基同意以“28点计划”为基础谈判,乌方将草案措辞改为“对战时行为全面大赦”
女子水杯内出现不明液体,查出是男同事所为,女子辞职后向公司索赔补偿被驳回
中国外交官在社交媒体上就日本首相高市早苗涉台表态发帖,是重新启动“战狼外交”?中方回应
10战9败!快船惨负魔术吞3连败 哈登三节31+5+8祖巴茨14+19
















