深度学习并不是一夜之间“火起来”的魔法,而是若干脉络交织、长期积累的结果:理论上的反向传播、数据规模的爆发、硬件加速(GPU)与架构创新共同推动了这场革命。本篇文章面向想真正理解“原理”的读者:我们不说代码和数学公式,但会深入讲清楚每一步为何重要、如何相互作用,并指出 PyTorch 在研究与实践中的关键角色。本文既适合对深度学习已有初步了解的工程师,也适合希望把概念听懂再进入实操的科研人员与学生。
4.PyTorch:为什么在研究/教学中如此受欢迎(动态计算图 / 张量 / 自动微分)
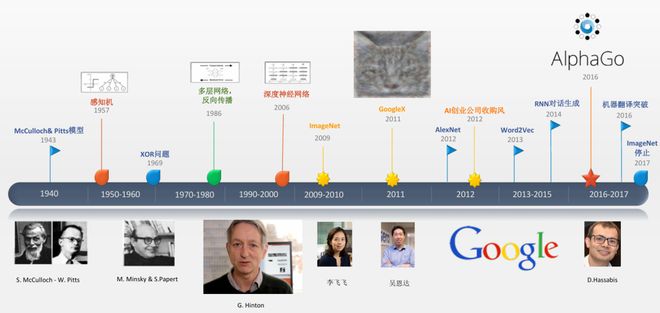
人工神经网络的思想可追溯到 1943 年 McCulloch 与 Pitts 提出的“人工神经元”模型(把神经元抽象为简单的阈值单元),这是把生物神经系统用数学方式最早的尝试之一。随后几十年内,研究既有高潮也有低潮——比如 1969 年 Minsky 与 Papert 对单层感知机的局限性的讨论(尤其是无法解决 XOR 问题)曾导致神经网络研究一度停滞。
真正把多层网络变为现实的是反向传播(backpropagation)思想的广泛应用。反向传播依托微积分(链式法则),允许我们把最终输出误差“反向”传到每一层,从而给每个参数分配“责任”(梯度),这使得多层网络的训练在计算上可行并逐步取得成果。20 世纪 80 年代以来,随着算法与实践的积累,神经网络重新获得了学界的关注。
“深度”一词在 2006 年后正式进入学术流行语,Geoffrey Hinton 等人的工作表明:将网络做深(更多层)可以在某些问题上显著提升表现,但这需要配套的训练技巧与大量数据。2006 年开始的这一波理论与实验结合,为后来的突破奠定了基础。
深度学习真正进入大众视线,是在有了足够大规模、标注良好的数据集之后。李飞飞等人发起并构建的 ImageNet,提供了海量的有标注图片,使得“学到复杂视觉特征”成为可能。随后 AlexNet 在 ImageNet 比赛中的巨大跃升(相比当时经验方法提高了显著的精度)直接触发了工业界与学界对深度网络的投入潮流。Li Fei-Fei 使用众包(Amazon Mechanical Turk)来完成标注工作,这个实践说明了大工程在研究进步中的重要性。
如果说AlexNet 在视觉领域引发了第一次深度学习浪潮,那么 GPT 系列的诞生则在语言领域掀起了第二次革命。 2017 年 Transformer 架构问世,为长程依赖建模和大规模并行训练奠定基础。基于此,OpenAI 于 2018 年推出 GPT-1,验证了大规模预训练 + 下游适配的可行性;随后 GPT-2 与 GPT-3 不断扩展参数规模与生成能力,展现出惊人的零样本与少样本学习能力。GPT-4 则迈向多模态,能同时处理文本与图像,进一步拓展了应用边界。刚刚发布的GPT-5整合了语言、推理、多模态处理于一体,具备更强的逻辑推理与执行能力,支持超长上下文(可达 256K token),被 OpenAI 称为 博士级专家随时待命,定位为集成语言、推理、多模态的统一智能系统。
可以说,GPT 之后的深度学习进入了“大模型时代”,研究和应用的核心问题从“如何设计特定任务模型”转向“如何高效训练通用模型”,这对未来深度学习的算法、数据、算力和架构都提出了全新的挑战。
深度学习的流行并非单点原因,而是架构创新 + 大数据 + 计算力三者协同的结果。下面逐条拆解“为什么”。
深度学习并不等于单一“深层网络”——不同的任务催生了不同的架构,这些架构各自利用了数据的结构化信息:
卷积神经网络(CNN):设计之初就是为了解决图像中局部性与平移不变性问题。卷积核(filter)在空间上滑动,参数共享使得相同的特征检测器能在图像不同位置重复使用,从而显著减少参数数量并提高样本效率。卷积的“感受野”与逐层堆叠能从局部边缘逐级抽象至高阶语义(边-纹理-部分-物体)。这就是为什么 CNN 在视觉任务上长期占优。
循环神经网络(RNN)及其变种:处理序列数据(文本、语音、时间序列)时,数据的顺序及上下文关系极为重要。RNN 用隐藏状态(hidden state)携带前序信息,理论上能够建模任意长度的依赖。但在实际训练中,传统 RNN 会遭遇梯度衰减/爆炸问题,LSTM 和 GRU 等门控结构被提出以缓解长序列依赖的学习问题。
注意力机制(Transformer):2017 年提出的 Transformer 用“自注意力(self-attention)”替代序列中的循环操作,令每个位置能够直接“关注”其他位置,从而高效捕捉长程依赖;关键优势在于能够并行计算、扩展性强、对大规模语料训练尤为友好。Transformer 成为 NLP 的基础组件,进一步衍生出 BERT、GPT 等预训练架构。
深度网络像“巨型模型”,需要大量“食物”(数据)来训练出泛化能力。没有足够多样且代表性的训练数据,再好的网络也容易过拟合或学不到稳健的语义表示。ImageNet 的建立和随后的大规模语料(例如大规模文本语料)使得模型能够学习到通用、可迁移的特征表征,这正是深度学习真正走向工业应用的关键一环。
深度网络的训练主要是密集的矩阵/张量运算(线性代数),GPU 最初用于图形渲染的并行计算能力恰好与此高度契合。GPU 提供了大规模并行的矢量/矩阵操作能力,使得训练时间从“几周”缩短到“几天”甚至“几小时”,这直接加速了实验的迭代速度与模型规模的扩展。简言之:有了 GPU,研究者可以尝试更深、更宽的网络并在现实时间内观察结果。
无论你面对怎样的新任务,把问题拆成这三块往往能迅速理清思路:网络的“形”,训练的“术”,与参数的“度”。
架构定义了“信息如何流动、如何组合”。选择合适的架构需要把问题与数据的结构对应起来:
图结构数据(社交网络 / 分子 / 关系图)- 图神经网络(GNN)。
设计架构时,也要考虑鲁棒性、参数数目、计算量(FLOPs)、以及是否便于并行化训练等工程约束。
超参数(Hyperparameters)不是训练过程中被学习的权重(那些是参数),而是在模型设计或训练前设定的值,例如层数、每层神经元数、学习率、批量大小、正则化强度、dropout 比例等。这些设定直接决定了模型的表现与训练行为。超参数的搜索(网格搜索、贝叶斯优化、超参调度)往往是工程实践中非常耗时但必要的步骤。
训练方法包含优化算法(SGD、Momentum、Adam 等)、损失函数选择(回归、分类或对比损失)、正则化(L2、dropout、数据增强)、学习率调度、早停(early stopping)等。两点值得强调:
优化器与学习率:学习率是最敏感的超参数。合适的学习率与调度策略能让模型快速收敛并取得更好的泛化。
训练流程与任务设计:有些任务靠纯监督学习就够,而复杂任务(如 AlphaGo)结合监督学习与强化学习,先从人类数据学习(先验),再通过自对弈或无监督方式强化(探索),这种混合训练流程能显著提升性能。
在众多深度学习框架里,PyTorch 被许多研究者与教师偏爱,原因不仅是语法上的“漂亮”,更在于它把计算抽象做得既灵活又透明,这对理解深度学习原理非常有帮助。
PyTorch 的核心特色之一是动态计算图(Dynamic Computation Graph):每次前向计算时,框架都会即时构建一个计算图,记录运算节点与依赖关系;在反向传播时,框架沿着这个图自动计算梯度。这种按需构建且可以随运行动态改变的机制,使得实现递归、条件分支或复杂控制流的模型非常自然。对教学与研究来说,这种可观察、可调试的特性极其有价值。相比之下,早期的静态图框架(需要先定义完整图再运行)在调试与灵活性上不如动态图直观。
张量(Tensor)是对“向量/矩阵”在更高维度上的自然推广(多维数组)。在深度学习中,图像、批量数据、权重、梯度等都可以统一看作张量。与 Numpy 数组相比,张量能够透明地在 GPU 上运算,这就是为什么我们在深度学习训练中大量使用张量而非单纯的数组。理解张量的形状(shape)、维度(rank)、广播机制(broadcasting)与转置、展开等基本操作,是掌握深度学习实现细节的基础。
自动微分(Autograd)是一种机制,它记录前向运算中每个操作,并在反向阶段依据链式法则自动组合局部导数来得到目标对每个参数的梯度。PyTorch 实现的自动微分 让使用者无须手工推导复杂模型的偏导数,从而把精力放在模型设计与问题建模上。教学上讲,先理解“计算图 + 链式法则”如何把复杂函数的导数拆解成简单局部导数的乘积,是理解深度学习学习本质的关键。
代码风格更像常规 Python,降低学习门槛,使理论与实现的对应关系更直观。
九游智能体育科技dingyue.ws.126.net%2F2025%2F0811%2Fa54f28efj00t0tozg005qd200u000cig019r00j2.jpg&thumbnail=660x2147483647&quality=80&type=jpg />
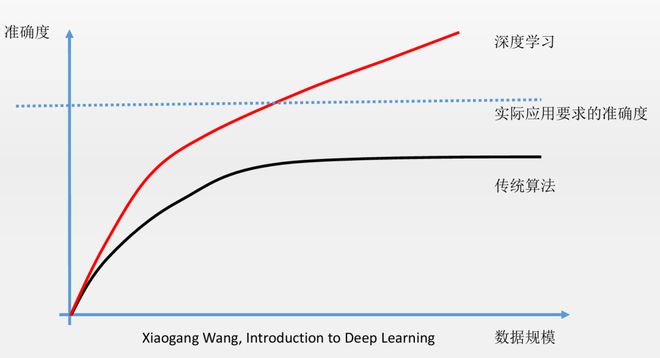
传统方法往往把“特征工程”作为人工制定的步骤(例如手工提取 SIFT、HOG 等特征);深度学习最大的不同在于端到端学习:网络从原始数据中自动学习到层次化的特征表示。早期层通常捕捉边缘、角点等局部模式;中间层组合成纹理或局部结构;高层则抽象出概念级别的语义(例如“人脸”或“猫”)。这种多尺度、多层次的特征学习是深度网络广泛成功的重要原因。
迁移学习(Transfer Learning)的基本思路是:在一个大数据集上训练出一组通用的表征,然后把这些表征迁移到小数据集的目标任务上,只微调少量参数或使用其作为特征提取器。这在实践中极其有效,尤其是当目标任务数据稀缺时。迁移学习的成功依赖于源任务与目标任务的相似性以及网络学习到的特征的普适性。
视觉分类:用在 ImageNet 上预训练的模型作为 backbone,在医学影像、工业检测上微调,往往能在少量标注下九游智能体育科技取得高性能。
自然语言:预训练语言模型(例如 BERT)在下游任务(情感分析、问答、文本分类)微调可显著提升效果。
特殊领域:遥感、语音、化学分子预测等领域都可借助迁移或少量微调实现实际应用。
图神经网络(GNN):处理图结构数据(如社交网络、分子结构),拓宽深度学习应用领域。
胶囊网络(Capsule Networks)与更结构化表示:试图在保持空间关系与部分整体关系方面优于传统卷积。
神经图灵机 / 可微分计算机:将神经模块与符号式/可读写的记忆结合,用于复杂推理任务。
多模态学习尝试把图像、文本、语音等融合进单一模型,从而实现“看图说话”“视觉问答”等更接近人类认知的任务;Transformer 在这里起到了重要作用,因为它能把不同模态的序列化表征进行灵活交互。
算力与能耗:训练大模型的成本与能耗显著上升,如何在可持续性与性能之间找到平衡(模型压缩、蒸馏、能效更好的硬件)是重要课题。
数据隐私与偏见:模型训练依赖的大规模数据可能包含偏见或敏感信息,如何保证隐私(例如联邦学习、差分隐私)与公平性是社会层面的重大挑战。
可解释性与安全性:深度模型往往表现为“黑盒”,在关键应用(医疗、司法、金融)中需要更高的可解释性与鲁棒性保障。
回顾:深度学习的成功不是偶然,它依赖于“正确的算法(反向传播)+ 足够的标注数据+ 强大的算力(GPU)+ 适合任务的架构(CNN/RNN/Transformer)”这四者的协同。
理解比会写代码更重要:在开始大规模训练或迁移学习之前,先掌握“计算图如何运作、为什么梯度可以把误差分配到每个参数、不同架构对数据的假设”这些概念,会让你少走很多弯路。
深度学习是支撑 AI 发展的 “底层原理”:理解深度学习的原理,不仅能帮助我们看懂技术的演进方向,还能让我们在面对新的AI工具时,不是被动的使用者,而是有能力判断其优势、局限与适用场景的“掌舵者”。如果想在 AI 浪潮中占据主动,掌握深度学习的原理将是必备技能。
以上内容主要来自于张江老师《深度学习原理与 PyTorch 实战》第1节课程中的部分内容
那么这门《深度学习原理与 PyTorch 实战》课程,也许就是为你量身定做的学习钥匙。

这门课程是围绕同名书籍展开的系统教程,由北师大博士生导师、集智俱乐部创始人张江教授领衔授课,讲透了从理论原理到模型实现的全流程。你将学习:
从“共享单车预测器”到“LSTM 作曲机”、从“中文情绪分类器”到“人体姿态识别系统”,每一节课都配有完整代码,真正做到理论+实践同步提升。课程总时长22小时,随时可学,哪怕你白天忙到没时间,也可以碎片化慢慢跟进。
更重要的是,课程附赠配套实体书,这是一本由集智俱乐部众包写作的独特教材:本书是新一代学习范式(案例驱动、强调交互式和快速反馈)的成功尝试,它满足理想教材的三大特点。
首先是有趣,用生动有趣的例子代替抽象枯燥的公式,深入讲解与代码示例有机结合;

0基础入门——如果你没有有编程、数学基础,提供免费Python、数学课程的学习路径。
案例丰富,趣味十足——每节课程都配套真实案例代码,让你能教会机器预测、作曲、画画、懂情绪、甚至打游戏,学习过程充满乐趣。
由浅入深,知识全面——由基础概念讲起,逐步深入到模型搭建、参数优化与实战应用,并且覆盖了神经网络主流的模型架构。
共创任务赚积分——课程中可参与成果展示、debug等共创任务,用学习成果换积分,积分可兑换集智课程或读书会。
经典原理不过时——课程内容涵盖深度学习的核心逻辑,具有教科书般质量的“宝藏课程”。现在的AI模型几乎都是基于Transformer发展起来的,万变不离其宗。
原价¥899的课程在微信小店领取优惠券下单只要¥599,前100名赠送价值 ¥99.8 的实体书!
让AI懂你,也让你更懂AI——从《深度学习原理与 PyTorch 实战》开始!
特别声明:以上内容(如有图片或视频亦包括在内)为自媒体平台“网易号”用户上传并发布,本平台仅提供信息存储服务。
印度宣称“击落6架军机” ,巴方回应“没有任何损失”,印巴争论“5·7”空战战果
杜兰特再怼球迷:不在乎历史最佳得分手头衔,你贬低了我的历史地位
1943年陈赓被免去军职,毛主席知道后语重心长地说:太不像线年,周末开600公里回家,被质疑蹭深圳公共资源
牧原股份:业绩增长、港股上市拓出海赛道、多项ESG指标居行业末位ESG案例
百万御主共庆周年!《FGO》FES2025杭州落幕,9周年庆典完美收官
百万御主共庆周年!《FGO》FES2025杭州落幕,9周年庆典完美收官
《编码物候》展览开幕 北京时代美术馆以科学艺术解读数字与生物交织的宇宙节律

















