【专栏介绍】⌈ ⌈ ⌈PyTorch深度学习 ⌋ ⌋ ⌋深度学习 (DL, Deep Learning) 特指基于深层神经网络模型和方法的机器学习。它是在统计机器学习、人工神经网络等算法模型基础上,结合当代大数据和大算力的发展而发展出来的。深度学习最重要的技术特征是具有自动提取特征的能力。神经网络算法、算力和数据是开展深度学习的三要素。深度学习在计算机视觉、自然语言处理、多模态数据分析、科学探索等领域都取得了很多成果。本专栏介绍基于PyTorch的深度学习算法实现。
之前首次介绍神经网络时,我们关注的是具有单一输出的线性模型。在这里,整个模型只有一个输出。注意,单个神经网络完成以下几项工作:(1)接受一些输入;(2)生成相应的标量输出;(3)具有一组相关参数(parameters),更新这些参数可以优化某目标函数。
然后,当考虑具有多个输出的网络时,我们利用矢量化算法来描述整层神经元。像单个神经元一样,层完成以下几项工作:(1)接受一组输入,(2)生成相应的输出,(3)由一组可调整参数描述。当我们使用softmax回归时,一个单层本身就是模型。然而,即使我们随后引入了多层感知机,我们仍然可以认为该模型保留了上面所说的基本架构。
对于多层感知机而言,整个模型及其组成层都是这种架构。整个模型接受原始输入(特征),生成输出(预测),并包含一些参数(所有组成层的参数集合)。同样,每个单独的层接收输入(由前一层提供),生成输出(到下一层的输入),并且具有一组可调参数,这些参数根据从下一层反向传播的信号进行更新。
事实证明,研究讨论比单个层大但比整个模型小的组件更有价值。例如,在计算机视觉中广泛流行的ResNet-152架构就有数百层,这些层是由层组(groups of layers)的重复模式组成。这个ResNet架构赢得了2015年ImageNet和COCO计算机视觉比赛的识别和检测任务。目前ResNet架构仍然是许多视觉任务的首选架构。在其他的领域,如自然语言处理和语音,层组以各种重复模式排列的类似架构现在也是普遍存在。
为了实现这些复杂的网络,我们引入了神经网络块的概念。块(block)可以描述单个层、由多个层组成的组件或整个模型本身。使用块进行抽象的一个好处是可以将一些块组合成更大的组件,这一过程通常是递归的,如图1所示。通过定义代码来按需生成任意复杂度的块,我们可以通过简洁的代码实现复杂的神经网络。
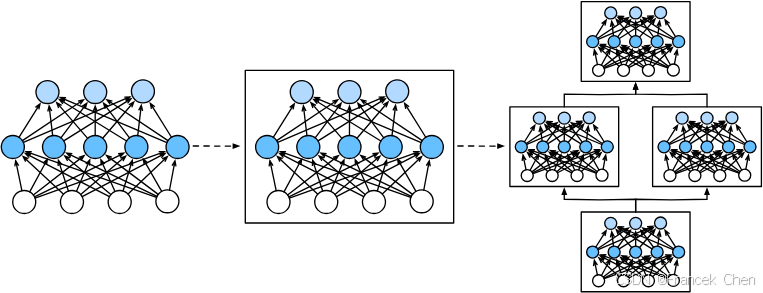
从编程的角度来看,块由类(class)表示。它的任何子类都必须定义一个将其输入转换为输出的前向传播函数,并且必须存储任何必需的参数。注意,有些块不需要任何参数。最后,为了计算梯度,块必须具有反向传播函数。在定义我们自己的块时,由于自动微分(在自动微分中引入)提供了一些后端实现,我们只需要考虑前向传播函数和必需的参数。
在构造自定义块之前,我们先回顾一下多层感知机的实现的代码。下面的代码生成一个网络,其中包含一个具有256个单元和ReLU激活函数的全连接隐藏层,然后是一个具有10个隐藏单元且不带激活函数的全连接输出层。
在这个例子中,我们通过实例化nn.Sequential来构建我们的模型,层的执行顺序是作为参数传递的。简而言之,nn.Sequential定义了一种特殊的Module,即在PyTorch中表示一个块的类,它维护了一个由Module组成的有序列表。注意,两个全连接层都是Linear类的实例,Linear类本身就是Module的子类。另外,到目前为止,我们一直在通过net(X)调用我们的模型来获得模型的输出。这实际上是net.__call__(X)的简写。这个前向传播函数非常简单:它将列表中的每个块连接在一起,将每个块的输出作为下一个块的输入。
要想直观地了解块是如何工作的,最简单的方法就是自己实现一个。在实现我们自定义块之前,我们简要总结一下每个块必须提供的基本功能。
在下面的代码片段中,我们从零开始编写一个块。它包含一个多层感知机,其具有256个隐藏单元的隐藏层和一个10维输出层。注意,下面的MLP类继承了表示块的类。我们的实现只需要提供我们自己的构造函数(Python中的__init__函数)和前向传播函数。
我们首先看一下前向传播函数,它以X作为输入,计算带有激活函数的隐藏表示,并输出其未规范化的输出值。在这个MLP实现中,两个层都是实例变量。要了解这为什么是合理的,可以想象实例化两个多层感知机(net1和net2),并根据不同的数据对它们进行训练。当然,我们希望它们学到两种不同的模型。
接着我们实例化多层感知机的层,然后在每次调用前向传播函数时调用这些层。注意一些关键细节:首先,我们定制的__init__函数通过super().__init__()调用父类的__init__函数,省去了重复编写模版代码的痛苦。然后,我们实例化两个全连接层,分别为self.hidden和self.out。注意,除非我们实现一个新的运算符,否则我们不必担心反向传播函数或参数初始化,系统将自动生成这些。
块的一个主要优点是它的多功能性。我们可以子类化块以创建层(如全连接层的类)、整个模型(如上面的MLP类)或具有中等复杂度的各种组件。我们在接下来的章节中充分利用了这种多功能性,比如在处理卷积神经网络时。
现在我们可以更仔细地看看Sequential类是如何工作的,回想一下Sequential的设计是为了把其他模块串起来。为了构建我们自己的简化的MySequential,我们只需要定义两个关键函数:
__init__函数将每个模块逐个添加到有序字典_modules中。大家可能会好奇为什么每个Module都有一个_modules属性?以及为什么我们使用它而不是自己定义一个Python列表?简而言之,_modules的主要优点是:在模块的参数初始化过程中,系统知道在_modules字典中查找需要初始化参数的子块。
当MySequential的前向传播函数被调用时,每个添加的块都按照它们被添加的顺序执行。现在可以使用我们的MySequential类重新实现多层感知机。
请注意,MySequential的用法与之前为Sequential类编写的代码相同(如多层感知机的实现中所述)。
Sequential类使模型构造变得简单,允许我们组合新的架构,而不必定义自己的类。然而,并不是所有的架构都是简单的顺序架构。当需要更强的九游体育科技灵活性时,我们需要定义自己的块。例如,我们可能希望在前向传播函数中执行Python的控制流。此外,我们可能希望执行任意的数学运算,而不是简单地依赖预定义的神经网络层。
在这个FixedHiddenMLP模型中,我们实现了一个隐藏层,其权重(self.rand_weight)在实例化时被随机初始化,之后为常量。这个权重不是一个模型参数,因此它永远不会被反向传播更新。然后,神经网络将这个固定层的输出通过一个全连接层。
注意,在返回输出之前,模型做了一些不寻常的事情:它运行了一个while循环,在 L 1 L_1 L1范数大于 1 1 1的条件下,将输出向量除以 2 2 2,直到它满足条件为止。最后,模型返回了X中所有项的和。注意,此操作可能不会常用于在任何实际任务中,我们只展示如何将任意代码集成到神经网络计算的流程中。
我们可以混合搭配各种组合块的方法。在下面的例子中,我们以一些想到的方法嵌套块。
大家可能会开始担心操作效率的问题。毕竟,我们在一个高性能的深度学习库中进行了大量的字典查找、代码执行和许多其他的Python代码。Python的问题全局解释器锁是众所周知的。在深度学习环境中,我们担心速度极快的GPU可能要等到CPU运行Python代码后才能运行另一个作业。


















